训练初始化
InternEvo 的训练流程可以归纳为两个步骤:
初始化
初始化模型、优化器、数据加载器、Trainer,生成不同种类的进程组,为混合并行的迭代训练做准备。
初始化Logger、Checkpoint管理器、Monitor管理器、Profiler,对迭代训练的过程观察、预警、记录。
迭代训练
根据配置文件定义的张量并行、流水线并行、数据并行的大小,加载训练引擎和调度器进行混合并行训练。
在迭代训练中,调用 Trainer API 进行梯度置零,前向传播计算损失并反向传播,参数更新。
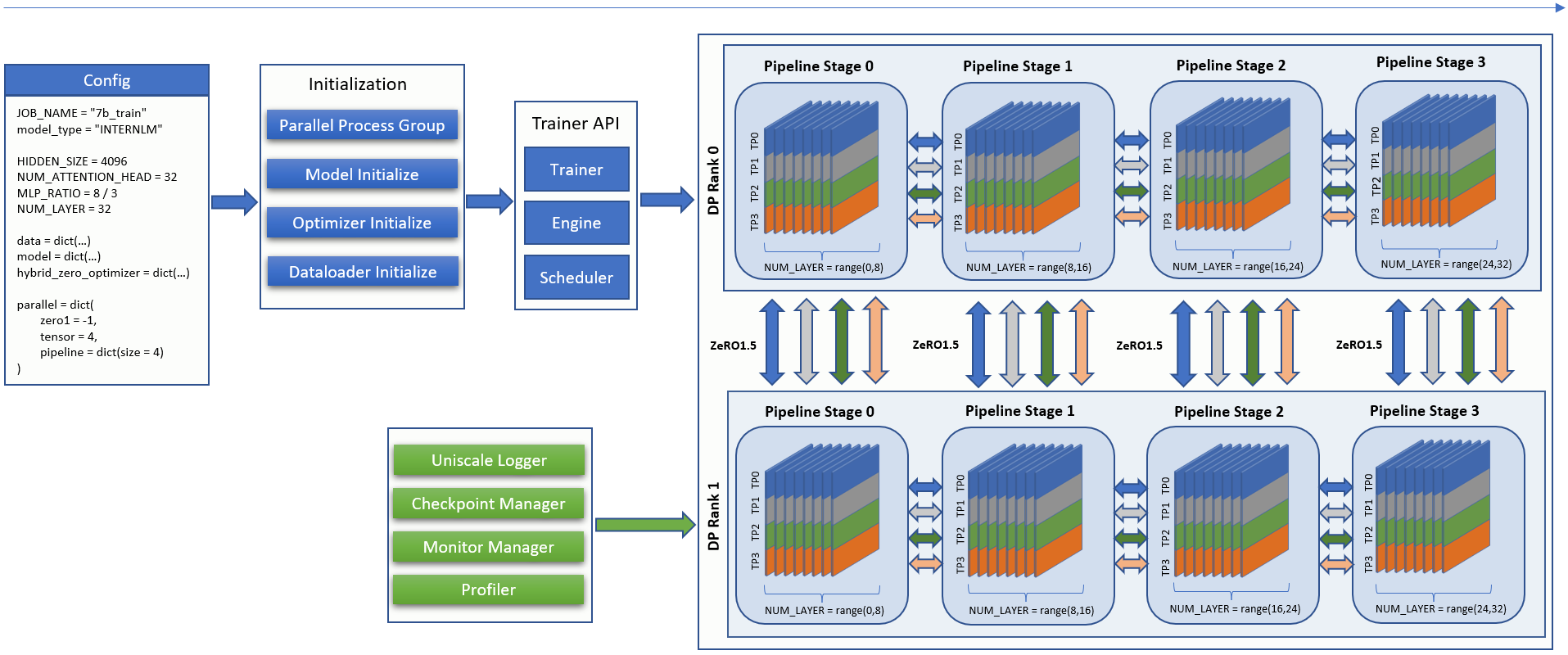
InternEvo训练流程图
命令行参数解析
InternEvo 使用 argparse 库来向InternEvo运行时提供命令行参数配置。
用户可使用 internlm.initialize.get_default_parser() 来获取 InternEvo 的默认解析器,其中包含一些内置参数,用户可以向此解析器添加自定义参数。
# Get InternEvo default parser
parser = internlm.initialize.get_default_parser()
# Add new argument
parser.add_argument("--user_arg", type=int, default=-1, help="arguments add by user.")
cmd_args = parser.parse_args()
模型初始化
InternEvo 在配置文件中使用字段 model_type 和 model 来控制模型初始化过程。示例模型初始化配置定义如下:
model_type = "INTERNLM" # default is "INTERNLM", used to register classes and modules for model initialization
NUM_ATTENTION_HEAD = 32
VOCAB_SIZE = 103168
HIDDEN_SIZE = 4096
NUM_LAYER = 32
MLP_RATIO = 8 / 3
model = dict(
checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1]
num_attention_heads=NUM_ATTENTION_HEAD,
embed_split_hidden=True,
vocab_size=VOCAB_SIZE,
embed_grad_scale=1,
parallel_output=True,
hidden_size=HIDDEN_SIZE,
num_layers=NUM_LAYER,
mlp_ratio=MLP_RATIO,
apply_post_layer_norm=False,
dtype="torch.bfloat16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32"
norm_type="rmsnorm",
layer_norm_epsilon=1e-5,
use_flash_attn=True,
num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used.
)
字段
model_type指明了要初始化的模型类型字段
model中的参数指定了在模型初始化过程中的参数设置
值得注意的是,用户可以定义新的模型类型,并通过 register_module 注册模型的初始化函数,示例如下所示:
model_initializer = Registry("model_initializer")
def register_model_initializer() -> None:
model_initializer.register_module("INTERNLM", InternLM1)
其中,”INTERNLM”为新的模型类型,InternLM1为新模型的入口函数。
数据加载器初始化
InternEvo 在配置文件中使用字段 data 来控制数据加载器初始化过程。示例数据加载器初始化配置定义如下:
TRAIN_FOLDER = None # "/path/to/dataset"
VALID_FOLDER = None # "/path/to/dataset"
data = dict(
seq_len=SEQ_LEN,
# micro_num means the number of micro_batch contained in one gradient update
micro_num=4,
# packed_length = micro_bsz * SEQ_LEN
micro_bsz=2,
# defaults to the value of micro_num
valid_micro_num=4,
# defaults to 0, means disable evaluate
valid_every=50,
pack_sample_into_one=False,
total_steps=50000,
skip_batches="",
# rampup_batch_size (str): A string with three space-separated integers representing the
# starting batch size, the increment, and the number of steps between
# each increment. For example, "192 24 8" means that the batch size (micro_num)
# starts at 192 and increases by 24 every 8 steps. Defaults to None.
# (IMPORTANT): The interval step size is 'micro_bsz'.
rampup_batch_size="",
# Datasets with less than 50 rows will be discarded
min_length=50,
train_folder=TRAIN_FOLDER,
valid_folder=VALID_FOLDER,
empty_cache_and_diag_interval=200,
diag_outlier_ratio=1.1,
# whether use shared memory to load meta files
use_shm=False,
# when use shm, the default shm_path is "/dev/shm/metacache"
# shm_path="/dev/shm/metacache"
)
这里支持三种数据集的初始化,包括模拟数据集、已分词数据集和流式数据集。
模拟数据集
如果设置TRAIN_FOLDER为None,则随机生成模拟数据集,如果设置的随机种子一样,生成的数据集保持一致。
已分词数据集
如果设置TRAIN_FOLDER为本地指定路径,路径中保存经过分词之后的.bin和.meta文件,则加载已分词数据集。
流式数据集
如果设置TRAIN_FOLDER为本地指定路径,路径中保存从huggingface下载的数据集,同时在data配置中,新增如下type和tokenizer_path字段,则加载流式数据集。
type="streaming",
tokenizer_path="/path/to/tokenizer",
已分词数据集和流式数据集格式的详细说明,参见 使用教程
并行通信初始化
通过 initialize_parallel_communicator 函数,初始化不同模式并行下的通信状态。
在 ISP 并行模式下,处理overlap优化,以及注册linear层的All_Gather通信。
在 MTP 并行模式下,分别注册被行切以及列切的权重的通信函数。
在 MSP 以及 FSP 并行模式下,注册序列并行的通信函数。
在 MoE 模型中,注册MoE序列化并行通信函数。
优化器初始化
InternEvo 在配置文件中使用字段 grad_scaler 、 hybrid_zero_optimizer 、 adam 、 lr_scheduler 和 beta2_scheduler 来控制优化器初始化过程。示例优化器初始化配置定义如下:
grad_scaler = dict(
fp16=dict(
# the initial loss scale, defaults to 2**16
initial_scale=2**16,
# the minimum loss scale, defaults to None
min_scale=1,
# the number of steps to increase loss scale when no overflow occurs
growth_interval=1000,
),
# the multiplication factor for increasing loss scale, defaults to 2
growth_factor=2,
# the multiplication factor for decreasing loss scale, defaults to 0.5
backoff_factor=0.5,
# the maximum loss scale, defaults to None
max_scale=2**24,
# the number of overflows before decreasing loss scale, defaults to 2
hysteresis=2,
)
hybrid_zero_optimizer = dict(
# Enable low_level_optimzer overlap_communication
overlap_sync_grad=True,
overlap_sync_param=False,
# bucket size for nccl communication params
reduce_bucket_size=512 * 1024 * 1024,
# grad clipping
clip_grad_norm=1.0,
# whether use new optm
use_split_tensor_optim=False,
# when use split tensor optm
# Perform all gather with a set of parameters of all_gather_size
all_gather_size=512 * 1024 * 1024,
)
adam = dict(
lr=1e-4,
adam_beta1=0.9,
adam_beta2=0.95,
adam_beta2_c=0,
adam_eps=1e-8,
weight_decay=0.01,
)
lr_scheduler = dict(
total_steps=data["total_steps"],
init_steps=0, # optimizer_warmup_step
warmup_ratio=0.01,
eta_min=1e-5,
last_epoch=-1,
)
beta2_scheduler = dict(
init_beta2=adam["adam_beta2"],
c=adam["adam_beta2_c"],
cur_iter=-1,
)
用户通过 initialize_optimizer 函数初始化优化器,并传入 isp_communicator 参数,以便处理 ISP 并行模式下的通信。
Trainer 初始化
通过initialize_trainer函数,初始化训练过程,需要输入创建好的模型、初始化的优化器以及调度器等参数。